Lec24 Shortest Paths
## 最短路的思想
为什么bfs不起作用:bfs倾向于选择节点少的路径,但若节点少的边权和大于节点多的边权和,结果就会出错
给予该图,寻找从A到每一个节点的最短路
可以发现,大多最短路径都包含了其他最短路径作为中间步骤,所有最短路倾向于重叠
实际上,我们可以说解决方案总是一颗树,即图的一个子树,我们想走最短路时,总是先走一个中间的最短路径,可以看作所有顶点上最短路径的并集,我们称这棵树为最短路径树(SPT)
若顶点数为V,则边数E总为V-1

接下来我们构建算法来寻找最短路
首先我们设定每个顶点都没有标记过,距离设为无穷,SPT中没有边

从A开始,将顶点A放入列表
当列表非空:
- 从列表中移除一个顶点并标记
- 对每个由v到w的边界,若不在SPT中存在,则添加该边,并将w放入列表

这显然不对,因为这种以BFS为基础的算法是按序处理距离起点1、2、3的顶点
若边权相同,则有效,否则会失效
接下来,尝试按边权将一条边分成若干小节点连成的边,小节点间的边边权都为1

这样可以获得正确结果,但我们创建了过多虚拟节点,且遍历的步数也会变多,这样会很慢很慢
抛去虚拟节点,这种算法访问节点的顺序可以成为最优优先顺序,我们接下来尝试按照该顺序遍历,但不创建虚拟节点
类似于BFS,但是这种情况下我们需要每次从列表中移除最近的边,选择使用优先队列追踪这个最近的边
添加A到列表
当列表非空:
- 从列表中移除距离最近的顶点并标记
- 对每个v到w,若w不是spt的一部分,则添加边,添加w到列表中

但结果仍然不正确,因为我们只考虑按最佳顶点来遍历,但每当计算出一条路径长度,我们就立即采用了该长度,但其实如果再等待一下,我们可以找到一条更短的路径
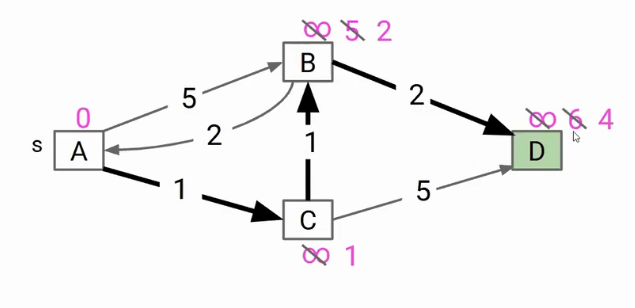
Dijkstra
该算法的思想在上面的基础上,暂定了最佳路径,并在稍后寻找更好的路径并覆盖先前的路径,这种方法叫做松弛。
具体步骤
将所有顶点添加到列表
若列表非空:
- 取出最接近的顶点并标记
- 对每一个边v到w,若该边使得到达w的距离更优,则添加该边,并更新列表中的w
伪代码
整体思路:
1
2
3
4
5
6
pq.add(source, 0)
for other vertices v:
pq.add(v, inf)
while !pq.empty():
p = pq.removesmallest()
relax all edges from p松弛一个边权为w,从p指向q的边:
1
2
3
4
if distTo[p]+w<distTo[q]:
distTo[q] = distTo[p]+w;
edgeTo[q] = p;
pq.changePriority(q, distTo[q]);- 我们总是按照距离起点的距离访问顶点
- 松弛不对已访问过的节点起作用(查看更差路径之前先查看更好的路径)
注意,dijkstra并不适用于负边权
复杂度

A*
若我们有一个想到达的终点,寻找最短路径,我们没有必要使用dijkstra将每条最短路径走一遍,而是在dijkstra的基础上添加一个启发式方法:预期到达终点需要的时间
设计一个启发式函数h(v, goal),得到到达终点的预期时间
故我们可以按照d(source, v)+h(v, goal)的顺序来访问顶点
即我们已经知道到达v的最短路,且我们推断v也是到达终点的最短路
启发式函数的设计
dijkstra可以看作将所有预期值设为0的启发式函数,任何启发式函数都可以实现算法,但我们需要遵循以下:
- 低估距离:h(v,goal)要小于等于从v到goal的真实值
- 持续性:对每一个w的邻居节点
h(v, goal)<=dist(v,w)+h(w,goal)dist(v,w)指从v到w的边权
最好的一种方法是使用地图上的直线距离,因为直线距离总会相等或比真实距离好