比特、字节与整数
信息存储
表示方法
计算机中的数据是以位(bit)为基本单元存储的
最小的可寻址的存储器单位为字节(byte),由8bits的块表示,而不是在存储器中访问单独的位
机器级程序将存储器视为一个非常大的字节数组,称为虚拟存储器,每个字节都有唯一地址标识,所有可能地址的集合称为虚拟地址空间
通常将4bits的数据分组并使用十六进制表示

进行十六转二进制转换时,可以一次进行一个十六进制值的转换
进行二转十六进制转换时,可以将二进制四位分一组进行转换,若少于四位前面用0补足
当值x是2的非负整数2次幂时,我们只需要记住此时x的二进制就是1后面n个0,而十六进制0代表四个二进制0,故我们可以将数分为\(i+4j\)的形式(\(0\leq i\leq3\))再转化为十六进制
字数据大小
每台计算机都有一个字长,指明了指针数据的标称大小,决定着虚拟地址空间的最大大小,即对于一个字长为w的机器而言,虚拟地址的范围为0~\(2^w-1\),程序最多访问\(2^w\)个字节
但计算机程序一般只能访问\(2^{47}\)的地址大小,某些内存是无法访问的,如果程序试图访问,则会抛出段错误(Segmentation Fault)
32位、64位机器之分就是按照字长大小进行区分的。大多64位机器可以向后兼容32位下编写的程式。而对32位与64位程序的区分是根据程序如何编译来决定的,而不是运行的机器类型
C中不同数据类型在32位和64位下的大小也是不同的
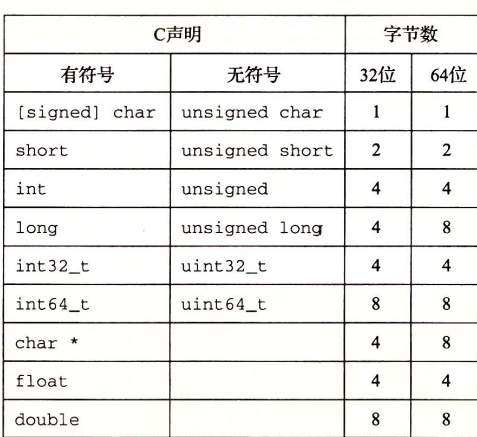
int32_t与int64_t是固定的数据大小,不随编译器和机器设置变化,分别为4字节与8字节- 大部分数据类型都编码为有符号值,除非有前缀
unsigned或对确定大小的数据使用特定声明。char类型是例外,大多编译器和机器将其认为是有符号数,C标准不保证 - 单精度float使用4字节,双精度double使用8字节
- gcc编译器下,,可以使用
-m32-m64来指定用多少位编译 - 某个程序使用的字长是由硬件和编译器共同决定的
寻址与字节顺序
在几乎所有机器上,多字节对象都被存储为连续的字节序列,地址为所使用字节
32位下字的地址是4的倍数,,64位下字的地址是8的倍数,这被称为对齐字节,编译器尽可能保持字对齐,使得硬件运行效率更高
考虑一个w位的整数,\(x_{w-1}\)为最高有效位\(x_0\)为最低有效位,若w是8的倍数,则这些位可以分为字节
机器选择在内存中按从最低有效字节到最高有效字节的顺序存储对象,即最低有效字节在前的方法称为小端法
机器选择在内存中按从最高有效字节到最低有效字节的顺序存储对象,即最高有效字节在前的方法称为大端法

大多数程序员来说,机器使用的字节顺序是完全不可见的,无论为哪种类型的机器所编译的程序都会得到同样的结果,但以下情况字节顺序会成为问题
一是不同类型的机器之间通过网络传输二进制数据时,小端机器产生的数据被发送到大端机器或反过来时,接收程序会发现字节称为反序,这时网络应用程序的代码编写需要遵循已建立的关于字节顺序的规则
二是当阅读表示整数数据的字节序列时,顺序也很重要,通常发生在检查机器级程序时。
如该行汇编代码4004d3: 01 05 43 0b 20 00 add %eax, 0x200b43(%rip),左侧的十六进制字节串的后四个字节反过来就是右侧的数值
三是当编写规避正常的类型系统的程序时,如在C语言中使用强制类型转换或联合来允许一种数据类型引用一个对象,而这种数据类型与创建对象时定义的数据类型不同
布尔代数
表示逻辑为将1表示为True,0表示为False
And(&):A&B=1当且仅当A=1且B=1
Or(|):A|B=1当A=1或B=1
Not():A=1当A=0
Xor(^):A^B=1当A=1或B=1且AB不同时为1
左移(<<):x<<y表示将x的二进制左移y个位置
左端多出的bits丢弃,右端用0填充
右移(>>):x>>y表示将x的二进制右移y个位置
右端多出的bits丢弃,对于左端有两种方法
- 逻辑移动:左端用0填充
- 算术移动:左端用最高有效位的值填充(默认使用该方法)
Java中,>>表示算术右移,>>>表示逻辑右移
注意:移位操作中移位量应该是一个0~n-1之间的数
若移位量\(y\geq x\)的位数(设为w),移位指令只考虑位移量的低\(\log_2w\)位
因为实际上位移量就是靠计算\(k\bmod{w}\)得到的
但这其实是一个未定义行为,故移位量最好还是要保证在范围内
位级运算
C语言支持位布尔运算,确定一个位级表达式的最好方法就是将十六进制的参数扩展成二进制并执行二进制运算,再转换回十六进制
一个常见用法是实现掩码运算
掩码是一个位模式,表从一个字中选出的位的集合
例:掩码0xFF表示一个字的低位字节,位级运算x&0x89ABCDEF生成一个由x的最低有效字节组成的值,而其他字节置零,如0x89ABCDEF变为0x000000EF。
表达式~0可以生成一个全1的掩码,不管机器的字大小是多少,等等
即掩码0xFF实现了选中x最低八位保留,掩码~0实现了获取所有位全一的掩码
整数表示
以下是会用到的术语

整型
整型数据类型指的是表示有限范围的整数
每种类型可以用关键字指定大小(char, short, long),同时可以只是被表示的数字是否有符号,分配的字节数根据机器字长决定,如下面是64位程序C语言整型的取值范围
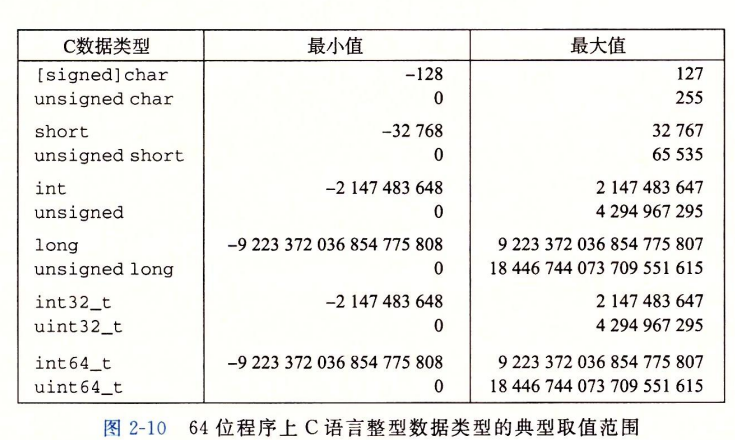
同时C语言标准定义了每种数据类型必须能表示的最小的取值范围,与上面的一样或小一些,只要求正数与负数的取值范围对称(除了int_t这种固定大小的)
定宽数据类型:
某些数据类型在不同的机器上有不同的取值范围,为了能够保持一致,我们需要定宽,即不能让某些整数类型随不同字节的机器而变化
故C99标准中引入了一组定宽整数类型,他们的声明类似于
intN_t与uintN_t,其中N可以为8、16、32、64等,与实现相关通过这种类型我们可以声明一个指定位数下的整数类型
除了类型本身,头文件中还定义了一套相匹配的宏,使用printf打印他们时,需要使用格式化宏,他们的名字类似于
PRIdN(有符号)与PRIuN(无符号),代码中表示如下:
printf("x = %" PRId32 ", y = %" PRIu64 "\n", x, y);他们本身就是字符串字面量,在不同系统中会被重定义为对应类型,如64位系统下,PRId32展开为d,PRId64展开为lu,故代码变为
printf("x = %d, y = %lu\n", x, y);这样保证了在不同机器上无论代码如何被编译都能生成正确的格式字符串
无符号数的编码
假设一个整数数据类型有w位,位向量为\(\vec{x}\)。将其看为一个二进制表示的数,就得到了无符号表示。
其中每一位\(x_i\)取值为0或1,取值1表示该位下\(2^i\)应成为数字值的一部分
即\(B2U_w(\vec{x})\doteq \sum_{i=0}^{w-1} x_i2^i\)
其中最小值位全是0,故为0;最大值位全是1,故为\(2^{w}-1\)
无符号的二进制表示有一个很重要的特性:每个介于范围之间的数都有唯一一个w位的值编码
因为函数\(B2U_w\)是一个双射
补码编码
计算机最常见的有符号数的表示方式是补码,在补码形式中,字的最高有效位\(x_{w-1}\)称为负权,也称为符号位,权重为\(-2^{w-1}\)
当符号位被设置为1时,表示值为负,设置为0时,表示值为非负
即\(B2T_w(\vec{x})\doteq -x_{w-1}2^{w-1}+\sum_{i=0}^{w-2} x_i2^i\)
其中最小值符号位为1,其余位为0,值为\(-2^{w-1}\),最大值符号位为0,其余位为1,值为\(2^{w-1}\)
同无符号,补码编码在可表示的取值范围内每一个数字都有一个唯一的w位补码编码
因为函数\(B2T_w\)也是一个双射
以下为一些比较重要的数字的表示
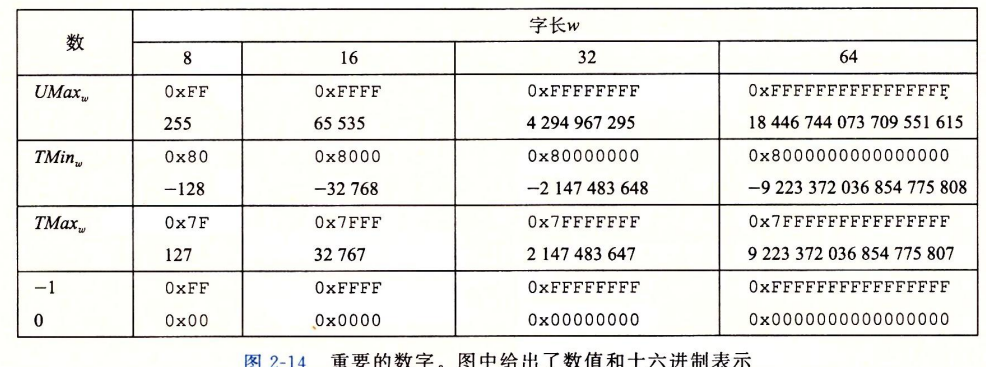
其中值得注意的是:
- 补码的范围是不对称的,这导致了补码运算中某些的特殊性质
- \(|TMin|=TMax+1\)
- 最大的无符号数刚好比补码最大值的两倍多1,即\(UMax_w=2TMax_w+1\)
其他表示方法
反码
除了最高有效位的权是\(-(2^{w-1}-1)\),其余与补码一致
\(B2O_w(\vec{x})\doteq -x_{w-1}(2^{w-1}-1)+\sum_{i=0}^{w-2} x_i2^i\)
原码
最高位为有效位,用来确定剩下的位该取负权还是正权
\(B2S_w(\vec{x})\doteq (-1)^{x_{w-1}}+\sum_{i=0}^{w-2} x_i2^i\)
这两种表示对于0有两种不同的编码方式:
- 将00…0都解释为+0
- 而-0在原码中表示为10…0,反码中表示为11…11
有符号与无符号数之间的转换
C语言允许在不同数据类型之间进行强制类型转换
对于有无符号数间的强转, 结果保持位值不变, 只是改变了解释位的方式
这可以总结为T2U函数的一个属性:
对满足\(TMin_w\leq x \leq TMax_w\)的x有:
\(T2U_w(x)=\left\{\begin{matrix} x+2^w, & x<0\\ x,&x\geq0\end{matrix}\right.\)
反过来, U2T函数的属性即为:
对满足\(0\leq u\leq UMax_w\)的u有:
\(U2T_w(u)=\left\{\begin{matrix} u, & x\leq TMax_w \\ u-2^w,&x>TMax_w \end{matrix}\right.\)
综上, 对于\(0\leq x\leq TMax_w\)之内的值x有着相同的无符号和补码表示
对于这个范围以外的值, 转换需要加上或减去\(2^w\)
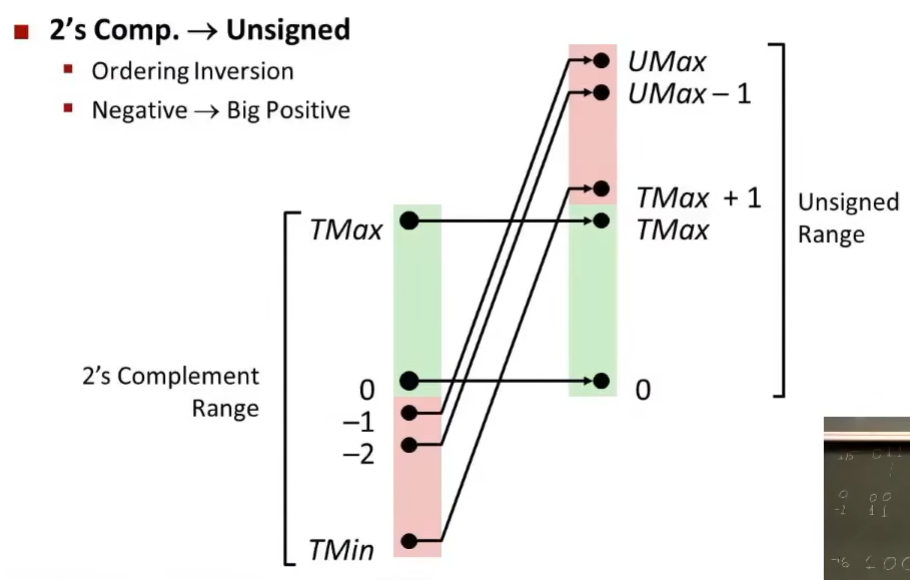
C语言中的有符号和无符号数
- C语言标准没有指定符号数用何种方式表示, 但几乎所有机器都使用补码
- 通常大部分数字默认为有符号数, 要创建一个无符号常量需要加上后缀u或U
- 进行转换时, 大多系统遵循的是底层的位保持不变, 即应用\(U2T_w\)与\(T2U_w\)函数,其中w为数据类型的位数
- 当一种类型的表达式被赋值给另一种类型的变量时, 发生隐式转换
- 在printf中使用%d, %u, %x分别表示有符号十进制, 无符号十进制, 十六进制. 当然也可以用%u输出int, 用%d输出unsigned, 此时会按照格式化的进行转换输出
- 若进行运算时一个运算数是有符号的另一个是无符号的, 那么C语言会隐式的将有符号强转为无符号, 并假设两个数都是非负来进行运算
C语言中TMin的写法:
C的头文件limits.h中, INT_MIN的宏定义为
#define INT_MIN (-INT_MAX - 1)这是补码的不对称性与C语言的转换规则结合起来迫使我们这么定义的
扩展一个数字的位表示
要将一个无符号数拓展为一个更大的数据类型, 只需要在开头添加0, 这种运算被称为零拓展,零拓展后数值大小不变,宽度变大
要将一个补码数拓展为一个更大的数据类型,可以执行符号拓展,在开头添加最高有效位的值(符号位的值),符号拓展后数值大小不变,宽度变大
注意:将一个数据向另一个数据转换以及无符号和有符号间转换的相对顺序会影响一个程序的行为,如将short转换为unsigned时,首先要改变大小再完成符号转换,即short->unsigned int而不是short->unsigned short
截断数字
当将一个w位的数截断为一个k位的数时,我们会丢弃高w-k位,此时可能会改变它的值
对于一个无符号数x,截断为k位后数值\(x'=x\bmod{2^k}\)
对于一个有符号数x的补码,截断为k位后数值\(x'=U2T_k(x\bmod2^k)\)
即将最高位转换为符号位,按照之前的定义需要减一个\(2^k\)
整数运算
无符号加法
考虑两个整数\(0\leq x,y\leq2^w\),他们的和的范围可能是\(0\leq x+y\leq2^{w+1}-2\),显然一个w位的数字可能需要w+1位才能表示。这种持续的字节膨胀意味着要完整表示算术运算的结果,我们不能对字长做任何限制
为参数x与y定义运算\(+^{u}_{w}\),其中\(0\leq x,y\leq2^w\),该操作是将\(x+y\)截断w位得到的结果,再把结果看作无符号数,即将原和模\(2^w\),具体的可以描述为
\(x+^{u}_{w}=\left\{\begin{matrix}x+y ,& x+y<2^w\\ x+y-2^w ,& 2^w\leq x+y\leq 2^{w+1}\end{matrix}\right.\)
C语言中不会将溢出作为错误发出信号,故我们可以写代码检测是否溢出:
对\(0\leq x,y \leq UMax_w\),令\(s\doteq x+^{u}_{w}y\),则对s,当且仅当\(s<x\)或等价的\(s<y\)时发生溢出
阿贝尔群:
模数加法形成了一种数学结构叫阿贝尔群,它是可交换和可结合的。有一个单位元0,并且每个元素有一个加法逆元
考虑w位的无符号数的集合,执行\(+^{u}_{w}\),对于每个值x,必然有某个值\(-^{u}_{w}x\)满足\(-^{u}_{w}x+^{u}_{w}x=0\),逆操作如下:
对满足\(0\leq x\leq2^w\)的任意x,其w位的无符号逆元\(-^{u}_{w}x\)由下式给出:
\(-^{u}_{w}x=\left\{\begin{matrix}x,& x=0\\2^w-x ,& x>0\end{matrix}\right.\)
补码加法
同样考虑两个整数\(-2^{w-1}\leq x,y\leq2^{w-1}-1\),他们的和的范围可能是\(-2^w\leq x+y\leq2^{w}-2\),要准确表示可能需要w+1位,但结果不太一样
定义\(x+^{t}_{w}y\)为\(x+y\)被截断w位的结果,并看作补码,则有:
\(x+^{t}_{w}y=\left\{\begin{matrix}x+y-2^w, & 2^{w-1}\leq x+y\\x+y,& -2^{w-1}\leq x+y<2^{w-1}\\x+y+2^w ,& x+y<-2^{w-1}\end{matrix}\right.\)
其中当和\(x+y\)超过\(TMax_w\)时,称发生了正溢出,结果会变为负数
当和\(x+y\)小于\(TMin_w\)时,称发生了**负溢出,结果会变为整数
检测补码加法中的溢出:
对满足\(TMin_w\leq x\leq TMax_w\)的x与y,令\(s\doteq x+^{u}_{w}y\),当且仅当\(x>0,y>0\)但\(s\leq0\)时发生了正溢出,当且仅当\(x<0, y<0\)但\(s\geq0\)时发生了负溢出
补码的非
注意到在\(TMin_w\leq x\leq TMax_w\)下的每个数字x都有\(+^{t}_{w}\)下的加法逆元,我们将补码的非\(-^{t}_{w}x\)表示如下:
\(-^{t}_{w}x=\left\{\begin{matrix}TMin_w, & x=TMin_w\\-x, & x>TMin_w\end{matrix}\right.\)
即对w位的补码加法来说,\(TMin_w\)是自己加法的逆,而对其他任何数值x都有-x作为其加法的逆
对于一个数的位级表示,计算补码非可以采取取反+1的方法,即\(-x=\textasciitilde x+1\)
还有一种方法是找到最低位1,将该位左边的所有位取反(不包括该位)
无符号乘法
\(0\leq x,y\leq2^w\)的两个数的乘积\(x\cdot y\)的取值范围\(0\leq x\cdot y \leq (2^w-1)^2\),这可能需要\(2w\)位表示,但C语言中的无符号乘积被定义为低w位表示的值,我们定义为\(x \times^{u}_{w}y\),则有:\(x \times^{u}_{w}y=(x\cdot y)\bmod{2^w}\)
补码乘法
\(-2^{w-1}\leq x,y\leq2^{w-1}-1\)的两个数的乘积的取值范围可能需要\(2w\)位表示,但C语言中表示的是截断后低w位的值,我们定义为\(x \times^{t}_{w}y\)。截断w位相当于先计算该值(无符号)模\(2^w\),再把无符号数转换为补码,即\(x \times^{t}_{w}y=U2T_w((x\cdot y)\bmod{2^w})\)
另外,我们认为对于无符号和补码乘法来说,他们结果的二进制表示都是一样的,即\(T2B_w(x \times^{t}_{w}y)=U2B_w(x \times^{u}_{w}y)\)
检测补码乘法中的溢出可以使用如下代码:
1
2
3
4
int tmult_ok(int x, int y){
int p = x*y;
return !x||p/x==y;
}乘以常数
在乘以常数因子时,编译器会尝试使用移位与加法来代替单纯相乘,可以提高运算速度
乘以2的幂
设x为w位的无符号整数,则对于任何\(k\geq0\),\(x2^w\)的\(w+k\)位的无符号表示表示为在原x二进制的右侧增加了k个0
如\(w=4\),11表示为1011,\(k=2\)时将其左移得到六位的101100,无符号数为44
进一步,结论还能简化为:
- 无符号乘法:变量x与k分别有无符号数值\(x\)与\(k\),且\(0\leq
k<w\),则表达式
x<<k可以得到\(x \times^{u}_{w}2^k\) - 补码乘法:变量x与k分别有补码值\(x\)与无符号数值\(k\),且\(0\leq
k<w\),则表达式
x<<k可以得到\(x \times^{t}_{w}2^k\)
如计算表达式x*14,编译器会将乘法重写为(x<<3)+(x<<2)+(x<<1)或者(x<<4)-(x<<1)
注意:乘以2的幂可能导致溢出,但结果表明,即使溢出得到的结果也是一样的,如1011移位得到101100,截断四位得到1100(\(12=44\bmod 16\))
乘以k
归纳上述例子,对于某个常数k的表达式x*k,编译器会把k的二进制表示表达为一组0和1交替的序列
如14可以写成[(0…0)(111)(0)]
考虑一组从位位置n到位位置m的连续的1,我们可以用以下两种形式中的一种来计算位对乘积的影响
- A:
(x<<n)+(x<<(n-1))+...+(x<<n) - B:
(x<<(n+1))-(x<<m)(当有效位最高位为n时,表达式改为-(x<<m))
把每个这样连续的1的结果加起来,不用做任何乘法就能计算出x*k
编译器对两种方式的选择:假设加减法有同样的性能
- 当n=m时,选择A,因为A只需要一个移位,而B需要两个移位和一个减法
- 当n=m+1时,选两者均可,都需要两个移位和一个加法或减法
- 当n>m+1时,选B,因为B只需要两个移位和一个减法,而A需要n-m+1>2个移位,B需要(n-m)>1个加法
补码除法(除以二的幂)
除以二的幂可以使用右移运算来实现,无符号和补码数分别使用逻辑移位与算术移位来达到目的
无符号运算
C语言下变量x与k分别有无符号数值\(x\)和\(k\),且\(0\leq
k<w\),则C表达式x>>k的值\(**\lfloor \frac{x}{2^k}
\rfloor\),此时右移获得的位向量左侧补零,是逻辑移位**
补码运算
为了使负数仍为负数,需要执行算术移位
对于\(x\geq0\),最高有效位为0,故效果与逻辑右移是一样的
对于\(x<0\),若需要进行舍入,结果会导致向下舍入,如右移四位时将会把-771.25向下舍为-772
故我们需要在移位之前通过偏置这个值,来修正不合适的舍入,即
C语言下变量x与k分别有无符号数值\(x\)和\(k\),且\(0\leq
k<w\),执行算术移位,C表达式(x+(1<<k)-1)>>k的值为\(\lceil \frac{x}{2^k} \rceil\)
其中偏置使用了如下属性:\(\lceil
\frac{x}{y} \rceil=\lfloor \frac{(x+y-1)}{y}
\rfloor\),而(x+(1<<k)-1)得到的数值即为\(x+2^k-1\),将该数右移k位就得到了\(\lceil \frac{x}{2^k} \rceil\)
在C语言中,使用(x<0? x+(1<<k)-1 : x)>>k可以计算\(\frac{x}{2^k}\)
注意:这种方法不能推广到除以任意常数k
使用建议
for循环中
在进行类似于for循环逆序遍历时,推荐使用size_t的64位数字类型来定义遍历变量,,防止无限循环
1
2
3
4size_t i;
for(i = cnt-2; i
何时使用无符号整数
- 进行模运算时时
- 当bits表示集合时